
Update 11/1/2017: While this is a very old post and SEO has changed a lot, I still believe that the basic point of this is valid.
Check out my SEO Brain Dump For more in-depth Search Engine Optimization Knowledge!
I have a great example to share that shows just how much a good link is worth.
I spend a lot of time working on SEO (Search Engine Optimization), both for myself and for clients/customers. There are a lot of “standard” questions I get asked, but one of the most common is “just how much do links really count?”
A few months ago, I was helping a client with a blog. I totally restructured and redesigned their blog. Their blog had been around a while, but only had 2 posts. I added 2 or 3 more posts before I started the redesign. Originally the blog had been in the root of the site, however, I changed that and ended up with the blog under a “blog” folder and a few “static” pages in the root of the site. I also changed the page naming scheme the blog was using.
The end result was that the search engines had indexed all 5 of the blog pages, but they were now in a different location with different names. If it was critical, I could have created files that matched those old names with a permanent redirect (301) to the new pages, but it wasn’t. I knew we’d take a hit for this, but it should not last long.
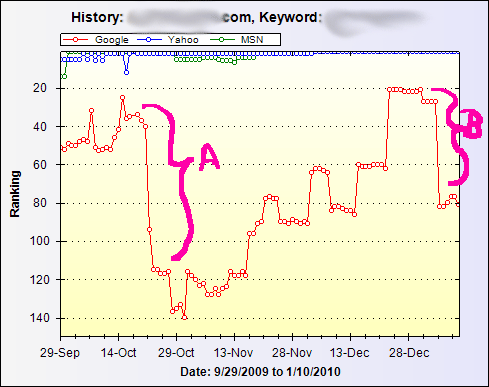
What’s the Value of a Link to SEO (Search Engine Optimization)?
I tracked the page rankings for a few keywords and we took a major hit (shown as drop “A”) in the graph. This occurred because I basically scrambled the site around and didn’t tell the search engines what I was doing. Notice that only Google seemed to care. And that we were pretty much ranking #1 or #2 on Yahoo and MSN (Bing) for the keyword phrase I was tracking.
There was another problem. This site was hosted on a Unix box using Apache as the web server (no, that’s not the problem). Because the blog was originally in the root of the site and because the blog software is WordPress, the rewrite engine was on for the root. But I had moved the blog from the root to a “blog” folder. So when a search engine spider would crawl the site, trying to locate the old pages with the old names (that no longer exist), they would get a partial, messed up, broken page – Instead of getting a 404 page not found, they were getting junk. Because of this, the old pages were not being removed from the search engine index, AND the search engines thought the site was garbage (but only Google seemed to care). Once I found the source of the problem and turn off the rewrite engine for the root, that problem was solved (somewhere near the end of October on the graph).
Back when I started working on their blog, I added a link to their blog from my blog. My blog has a Google Page Rank of 3, so it has some decent value.
You can see over time and with more SEO effort on my part, such as submitting articles, etc. their ranking in Google improved for the keyword phrase I was tracking.
Toward the end of December that client became a non-client. I was cleaning up my blogroll around the end of the year and decided to remove their link. Look at the drop at “B” on the graph – that is the result. As far as I know, that’s the ONLY thing that changed! It’s hard to tell from the graph, but the drop occurred on January 5th 2010.
Notice again, Google is the only one that cared. Their blog is still pegged at #1 on Yahoo and MSN(Bing) for the phrase I’m tracking.
Why did Google care when Yahoo and MSN(Bing) did not? I’m not totally sure except that it appears that Google is much more sensitive to problems on your site, drastic changes, etc.
But this does show the value, especially on small, fairly new sites with not many inbound links, of good, solid, one-way links from sites with good page rank.
Until Next Time,
Fred
 [addtoany]
[addtoany]